We provide in two formats. Download PDF & Practice Tests. Pass Microsoft 70-767 Exam quickly & easily. The 70-767 PDF type is available for reading and printing. You can print more and practice many times. With the help of our product and material, you can easily pass the 70-767 exam.
Free 70-767 Demo Online For Microsoft Certifitcation:
NEW QUESTION 1
You are implementing a Microsoft SQL Server data warehouse with a multi-dimensional data model. Orders are stored in a table named Factorder. The addresses that are associated with all orders are stored in a fact table named FactAddress. A key in the FoctAddress table specifies the type of address for an order.
You need to ensure that business users can examine the address data by either of the following:
• shipping address and billing address
• shipping address or billing address type Which data model should you use?
- A. star schema
- B. snowflake schema
- C. conformed dimension
- D. slowly changing dimension (SCD)
- E. fact table
- F. semi-additive measure
- G. non-additive measure
- H. dimension table reference relationship
Answer: H
NEW QUESTION 2
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications. The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer,
Dimension.Date, Fact.Ticket, and Fact.Order. The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated. The Fact.Order table is optimized for weekly reporting, but the company wants to change it daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements: Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible. Partition the Fact.Order table and retain a total of seven years of data. Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed. Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.
Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible. Partition the Fact.Order table and retain a total of seven years of data. Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed. Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables. Maximize the performance during the data loading process for the Fact.Order partition. Ensure that historical data remains online and available for querying. Reduce ongoing storage costs while maintaining query performance for current data.
Maximize the performance during the data loading process for the Fact.Order partition. Ensure that historical data remains online and available for querying. Reduce ongoing storage costs while maintaining query performance for current data.
You are not permitted to make changes to the client applications. You need to implement partitioning for the Fact.Ticket table.
Which three actions should you perform in sequence? To answer, drag the appropriate actions to the correct locations. Each action may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: More than one combination of answer choices is correct. You will receive credit for any of the correct combinations you select.
Answer:
Explanation: From scenario: - Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
The detailed steps for the recurring partition maintenance tasks are: References:
https://docs.microsoft.com/en-us/sql/relational-databases/tables/manage-retention-of-historical-data-in-system-v
NEW QUESTION 3
You deploy a Microsoft Azure SQL Data Warehouse instance. The instance must be available eight hours each day.
You need to pause Azure resources when they are not in use to reduce costs.
What will be the impact of pausing resources? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Answer:
Explanation: To save costs, you can pause and resume compute resources on-demand. For example, if you won't be using the database during the night and on weekends, you can pause it during those times, and resume it during the day. You won't be charged for DWUs while the database is paused.
When you pause a database:
Compute and memory resources are returned to the pool of available resources in the data center Data Warehouse Unit (DWU) costs are zero for the duration of the pause.
Data storage is not affected and your data stays intact.
SQL Data Warehouse cancels all running or queued operations. When you resume a database:
SQL Data Warehouse acquires compute and memory resources for your DWU setting. Compute charges for your DWUs resume.
Your data will be available.
You will need to restart your workload queries. References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-manage-compute-rest-api
NEW QUESTION 4
You have a Microsoft SQL Server Integration Services (SSIS) package that contains a Data Flow task as shown in the Data Flow exhibit. (Click the Exhibit button.)
You install Data Quality Services (DQS) on the same server that hosts SSIS and deploy a knowledge base to manage customer email addresses. You add a DQS Cleansing transform to the Data Flow as shown in the Cleansing exhibit. (Click the Exhibit button.)
You create a Conditional Split transform as shown in the Splitter exhibit. (Click the Exhibit button.)
You need to split the output of the DQS Cleansing task to obtain only Correct values from the EmailAddress column.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
Answer:
Explanation: The DQS Cleansing component takes input records, sends them to a DQS server, and gets them back corrected. The component can output not only the corrected data, but also additional columns that may be useful for you. For example - the status columns. There is one status column for each mapped field, and another one that aggregated the status for the whole record. This record status column can be very useful in some scenarios, especially when records are further processed in different ways depending on their status. Is such cases, it is recommended to use a Conditional Split component below the DQS Cleansing component, and configure it to split the records to groups based on the record status (or based on other columns such as specific field status).
References: https://blogs.msdn.microsoft.com/dqs/2011/07/18/using-the-ssis-dqs-cleansing-component/
NEW QUESTION 5
You have a database that contains a table named Email. Change Data Capture (CDC) is enabled for the table. You have a Microsoft SQL Server Integration Services (SSIS) package that contains the Data Flow task shown in the Data Flow exhibit. (Click the Exhibit button.)
You have an existing CDC source as shown in the CDC Source exhibit (Click the Exhibit button)
and a CDC Splitter transform as shown in the CDC Splitter exhibit. (Click the Exhibit button.)

You need to perform an incremental import of customer email addresses. Before importing email addresses, you must move all previous email addresses to another table for later use.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Answer:
Explanation: Yes
Yes Yes No
NEW QUESTION 6
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in the series.
Start of repeated scenario
Contoso. Ltd. has a Microsoft SQL Server environment that includes SQL Server Integration Services (SSIS), a data warehouse, and SQL Server Analysis Services (SSAS) Tabular and multidimensional models.
The data warehouse stores data related to your company sales, financial transactions and financial budgets. All data for the data warenouse originates from the company's business financial system.
The data warehouse includes the following tables:
The company plans to use Microsoft Azure to store older records from the data warehouse. You must modify the database to enable the Stretch Database capability.
Users report that they are becoming confused about which city table to use for various queries. You plan to create a new schema named Dimension and change the name of the dbo.du_city table to Diamension.city. Data loss is not permissible, and you must not leave traces of the old table in the data warehouse.
Pal to create a measure that calculates the profit margin based on the existing measures.
You must implement a partitioning scheme few the fact. Transaction table to move older data to less expensive storage. Each partition will store data for a single calendar year, as shown in the exhibit (Click the Exhibit button.) You must align the partitions.
You must improve performance for queries against the fact.Transaction table. You must implement appropriate indexes and enable the Stretch Database capability.
End of repeated scenario
You need to resolve the problems reported about the dia city table.
How should you complete the Transact-SQL statement? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact-SQL segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
Answer:
Explanation: 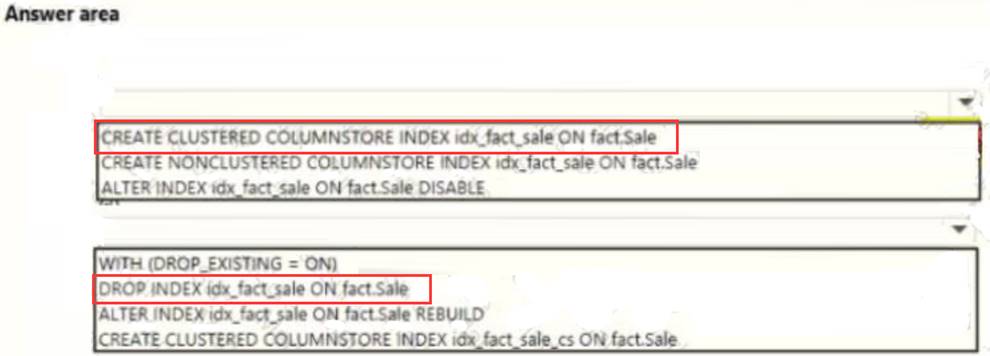
NEW QUESTION 7
You administer a Microsoft SQL Server Master Data Services (MDS) model. All model entity members have passed validation.
The current model version should be committed to form a record of master data that can be audited and create a new version to allow the ongoing management of the master data.
You lock the current version. You need to manage the model versions.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area, and arrange them in the correct order.
Answer:
Explanation: Box 1: Validate the current version.
In Master Data Services, validate a version to apply business rules to all members in the model version. You can validate a version after it has been locked.
Box 2: Commit the current version.
In Master Data Services, commit a version of a model to prevent changes to the model's members and their attributes. Committed versions cannot be unlocked.
Prerequisites:
Box 3: Create a copy of the current version.
In Master Data Services, copy a version of the model to create a new version of it. Note:
References:
NEW QUESTION 8
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have a database named DB1 that has change data capture enabled.
A Microsoft SQL Server Integration Services (SSIS) job runs once weekly. The job loads changes from DB1 to a data warehouse by querying the change data captule tables.
You remove the Integration Services job.
You need to stop tracking changes to the database temporarily. The solution must ensure that tracking changes can be restored quickly in a few weeks.
Which stored procedure should you execute?
- A. catalog.deploy_project
- B. catalog.restore_project
- C. catalog.stop.operation
- D. sys.sp_cdc.addJob
- E. sys.sp.cdc.changejob
- F. sys.sp_cdc_disable_db
- G. sys.sp_cdc_enable_db
- H. sys.sp_cdc.stopJob
Answer: C
Explanation: catalog.stop_operation stops a validation or instance of execution in the Integration Services catalog.
References:
https://docs.microsoft.com/en-us/sql/integration-services/system-stored-procedures/catalog-stop-operation-ssisd
NEW QUESTION 9
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
Each night you receive a comma separated values (CSV) file that contains different types of rows. Each row type has a different structure. Each row in the CSV file is unique. The first column in every row is named Type. This column identifies the data type.
For each data type, you need to load data from the CSV file to a target table. A separate table must contain the number of rows loaded for each data type.
Solution: You create a SQL Server Integration Services (SSIS) package as shown in the exhibit. (Click the
Exhibit tab.)
Does the solution meet the goal?
- A. Yes
- B. NO
Answer: B
Explanation: The conditional split must be before the count.
NEW QUESTION 10
You need to recommend a storage solution for a data warehouse that minimizes load times. The solution must provide availability if a hard disk fails.
Which RAID configuration should you recommend for each type of database file? To answer, drag the appropriate RAID configurations to the correct database file types. Each RAID configuration may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: Box 1: RAID 5
RAID 5 is the similar to that of RAID 0 provided that the number of disks is the same. However, due to the fact that it is useless to read the parity data, the read speed is just (N-1) times faster but not N times as in RAID 0.
Box 2: RAID 10
Always place log files on RAID 1+0 (or RAID 1) disks. This provides better protection from hardware failure, and better write performance.
Note: In general RAID 1+0 will provide better throughput for write-intensive applications. The amount of performance gained will vary based on the HW vendor’s RAID implementations. Most common alternative to RAID 1+0 is RAID 5. Generally, RAID 1+0 provides better write performance than any other RAID level providing data protection, including RAID 5.
NEW QUESTION 11
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these
questions will not appear in the review screen.
You have a Microsoft SQL server that has Data Quality Services (DQS) installed. You need to review the completeness and the uniqueness of the data stored in the matching policy. Solution: You modify the weight of the domain in the matching rule.
Does this meet the goal?
- A. Yes
- B. No
Answer: A
Explanation: Use a matching rule, and use completeness and uniqueness data to determine what weight to give a field in the matching process.
If there is a high level of uniqueness in a field, using the field in a matching policy can decrease the matching results, so you may want to set the weight for that field to a relatively small value. If you have a low level of uniqueness for a column, but low completeness, you may not want to include a domain for that column.
References:
https://docs.microsoft.com/en-us/sql/data-quality-services/create-a-matching-policy?view=sql-server-2021
NEW QUESTION 12
You need to configure Microsoft SQL Server Integration Services (SSIS) for maximum insert performance. The Integration Services package is configured as shown in the following exhibit.

Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: Table or view Check contraints
NEW QUESTION 13
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database administrator for an e-commerce company that runs an online store. The company has the databases described in the following table.
Product prices are updated and are stored in a table named Products on DB1. The Products table is deleted and refreshed each night from MDS by using a Microsoft SQL Server Integration Services (SSIS) package. None of the data sources are sorted.
You need to update the SSIS package to add current prices to the Products table. What should you use?
- A. Lookup transformation
- B. Merge transformation
- C. Merge Join transformation
- D. MERGE statement
- E. Union All transformation
- F. Balanced Data Distributor transformation
- G. Sequential container
- H. Foreach Loop container
Answer: D
Explanation: In the current release of SQL Server Integration Services, the SQL statement in an Execute SQL task can contain a MERGE statement. This MERGE statement enables you to accomplish multiple INSERT, UPDATE, and DELETE operations in a single statement.
References:
https://docs.microsoft.com/en-us/sql/integration-services/control-flow/merge-in-integration-services-packages
NEW QUESTION 14
You have the Microsoft SQL Server Integration Services (SSIS) package shown in the Control flow exhibit. (Click the Exhibit button.)
The package iterates over 100 files in a local folder. For each iteration, the package increments a variable named loop as shown in the Expression task exhibit. (Click the Exhibit button) and then imports a file. The initial value of the variable loop is 0.
You suspect that there may be an issue with the variable value during the loop. You define a breakpoint on the Expression task as shown in the BreakPoint exhibit. (Click the Exhibit button.)
You need to check the value of the loop variable value.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Answer:
Explanation: Break condition: When the task or container receives the OnPreExecute event.
Called when a task is about to execute. This event is raised by a task or a container immediately before it runs. The loop variable does not reset.
With the debugger, you can break, or suspend, execution of your program to examine your code, evaluate and edit variables in your program, etc.
NEW QUESTION 15
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are developing a Microsoft SQL Server Integration Services (SSIS) package. The package design consists of two differently structured sources in a single data flow. The Sales source retrieves sales transactions from a SQL Server database, and the Product source retrieves product details from an XML file.
You need to combine the two data flow sources into a single output dataset. Which SSIS Toolbox item should you use?
- A. CDC Control task
- B. CDC Splitter
- C. Union All
- D. XML task
- E. Fuzzy Grouping
- F. Merge
- G. Merge Join
Answer: G
Explanation: The Merge Join transformation provides an output that is generated by joining two sorted datasets using a FULL, LEFT, or INNER join. For example, you can use a LEFT join to join a table that includes product information with a table that lists the country/region in which a product was manufactured. The result is a table that lists all products and their country/region of origin.
References:
https://docs.microsoft.com/en-us/sql/integration-services/data-flow/transformations/merge-join-transformation
NEW QUESTION 16
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have a database named DB1.
You need to track auditing data for four tables in DB1 by using change data capture. Which stored procedure should you execute first?
- A. catalog.deploy_project
- B. catalog.restore_project
- C. catalog.stop_operation
- D. sys.sp_cdc_add_job
- E. sys.sp_cdc_change_job
- F. sys.sp_cdc_disable_db
Answer: D
Explanation: Because the cleanup and capture jobs are created by default, the sys.sp_cdc_add_job stored procedure is necessary only when a job has been explicitly dropped and must be recreated.
Note: sys.sp_cdc_add_job creates a change data capture cleanup or capture job in the current database. A cleanup job is created using the default values when the first table in the database is enabled for change data capture. A capture job is created using the default values when the first table in the database is enabled for change data capture and no transactional publications exist for the database. When a transactional publication exists, the transactional log reader is used to drive the capture mechanism, and a separate capture job is neither required nor allowed.
Note: sys.sp_cdc_change_job
References:
https://docs.microsoft.com/en-us/sql/relational-databases/track-changes/track-data-changes-sqlserver
Thanks for reading the newest 70-767 exam dumps! We recommend you to try the PREMIUM 2passeasy 70-767 dumps in VCE and PDF here: https://www.2passeasy.com/dumps/70-767/ (109 Q&As Dumps)